探索式資料分析 (Exploratory Data Analysis, EDA),主要概念是利用數據統計的方式視覺化資料。透過資料的探索式分析可以查看資料集當中每個特徵彼此的重要程度以及其資料分布狀況,有良好的數據分析習慣能夠幫助你更了解資料集的特性。另外做 EDA 的好處是可以從各種面向先了解資料的狀況,以利後續的模型分析。

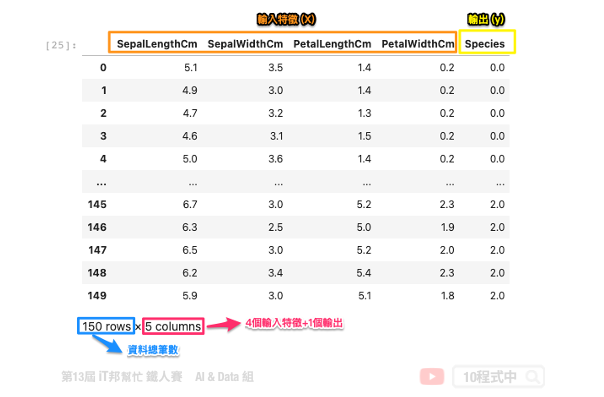
此資料集總共有4個輸入特徵。分別為花萼長度、花萼寬度、花瓣長度與花瓣寬度。輸出特徵為花朵的品種,共有三種類別分別為 0: iris setosa、 1: iris versicolor、 2: iris virginica。

首先我們載入資料探索式分析所需的套件。分別有進行數據處理的函式庫的pandas、高階大量的維度陣列與矩陣運算的 numpy、處理資料視覺化的繪圖庫 matplotlib 與 seaborn。最後一個是資料集來源,此系列範例我們採用 Sklearn 所提供的鳶尾花分類的資料集。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
Sklearn 套件中提供了七個快速入門的 Toy datasets 很推薦初學者可以載入來玩玩看,並且練習做資料探索與建模。每一個資料集呼叫的方法非常簡單。以鳶尾花朵資料集為例,我們可以透過 API 取得輸入與輸出。
from sklearn.datasets import load_iris
iris = load_iris()
# 輸入特徵
X = iris.data
# 輸出特徵
y = iris.target
Sklearn 提供了許多 API 方法可以呼叫:
如果想試試其他的資料集可以參考:
首先我們載入鳶尾花朵資料集。為了方便分析我們將 numpy 格式的資料轉換成 DataFrame 的格式進行資料探索。因為透過 Pandas 的 DataFrame 格式我們更能用表格的形式觀察資料。
iris = load_iris()
df_data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= ['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species'])
df_data
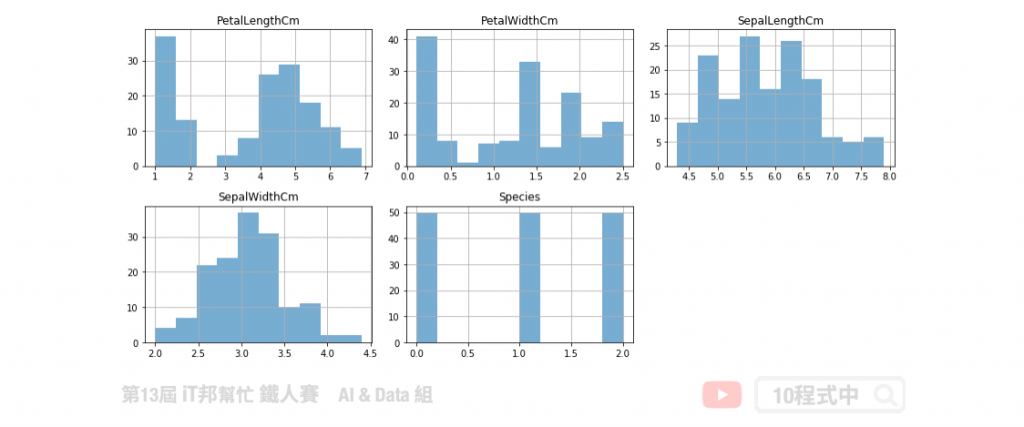
直方圖是一種對數據分布情況的圖形表示,是一種二維統計圖表。我們可以直接呼叫 Pandas 內建函式 hist() 進行直方圖分析。其中我們可以設定 bins(箱數),預設值為 10。如果設定的輸量越大,其代表需要分割的精度越細。通常取一個適當的箱數即可觀察該特徵在資料集中的分佈情況。藉由直方圖我們可以知道每個值域的分佈大小與數量。我們也能發現輸出項的類別共有三個,並且這三個類別的數量都剛好各有 50 筆資料。我們也能得知這一份資料集的輸出類別是一個非常均勻的資料。
#直方圖 histograms
df_data.hist(alpha=0.6,layout=(3,3), figsize=(12, 8), bins=10)
plt.tight_layout()
plt.show()
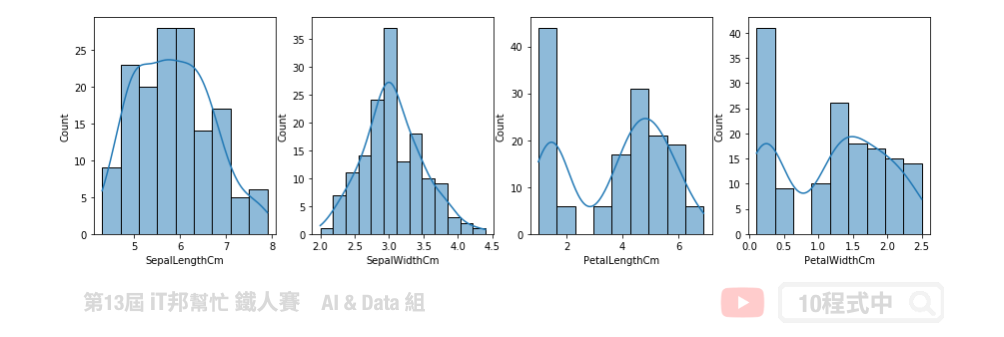
我們也可以透過 Seaborn 的 histplot 做出更詳細的直方圖分析。並利用和密度估計 kde=True 來查看每個特徵的分佈狀況。
fig, axes = plt.subplots(nrows=1,ncols=4)
fig.set_size_inches(15, 4)
sns.histplot(df_data["SepalLengthCm"][:],ax=axes[0], kde=True)
sns.histplot(df_data["SepalWidthCm"][:],ax=axes[1], kde=True)
sns.histplot(df_data["PetalLengthCm"][:],ax=axes[2], kde=True)
sns.histplot(df_data["PetalWidthCm"][:],ax=axes[3], kde=True)
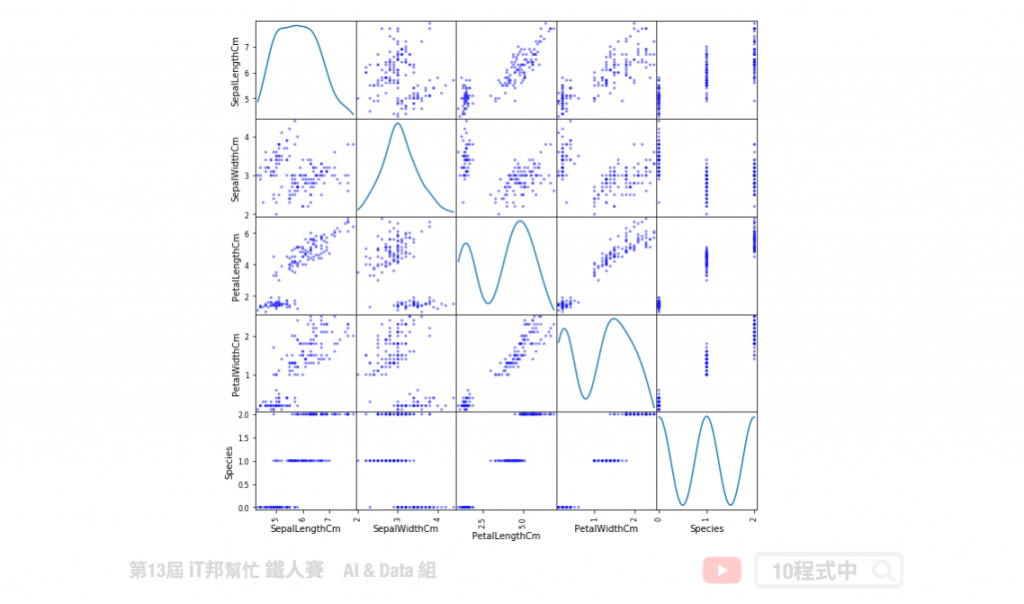
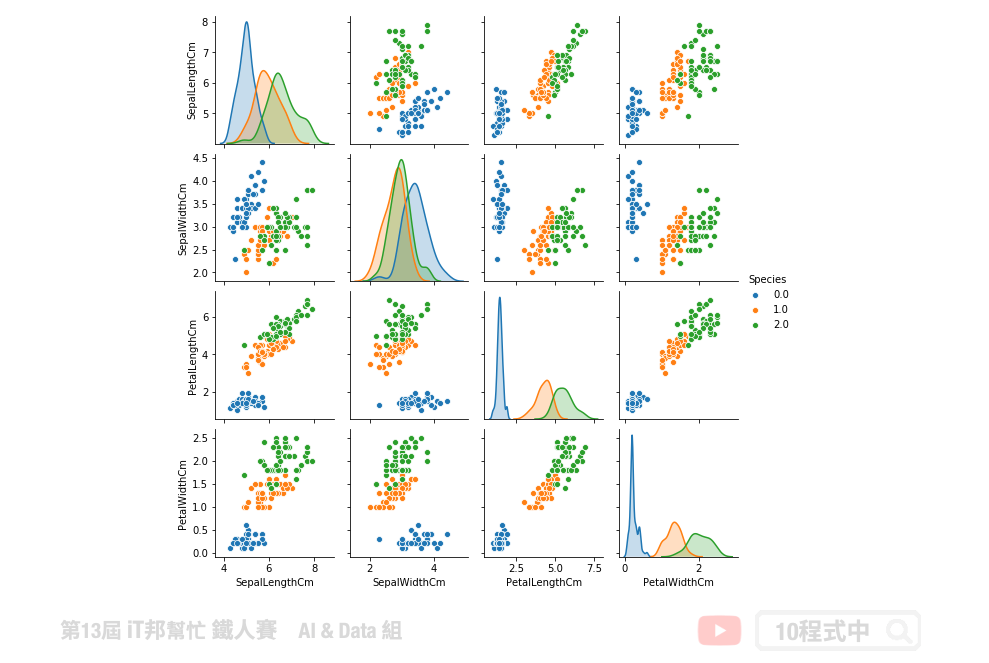
核密度估計分爲兩部分,分別有對角線部分和非對角線部分。在對角線部分是以核密度估計圖(Kernel Density Estimation)的方式呈現,也就是用來看某一個特徵的分佈情況,x軸對應著該特徵的數值,y軸對應著該特徵的密度也就是特徵出現的頻率。在非對角線的部分為兩個特徵之間分佈的關聯散點圖。將任意兩個特徵進行配對,以其中一個爲橫座標,另一個爲縱座標,將所有的數據點繪製在圖上,用來衡量兩個變量的關聯程度。
使用 Pandas 繪製:
from pandas.plotting import scatter_matrix
scatter_matrix( df_data,figsize=(10, 10),color='b',diagonal='kde')
使用 Seaborn 繪製:
sns.pairplot(df_data, hue="Species", height=2, diag_kind="kde")
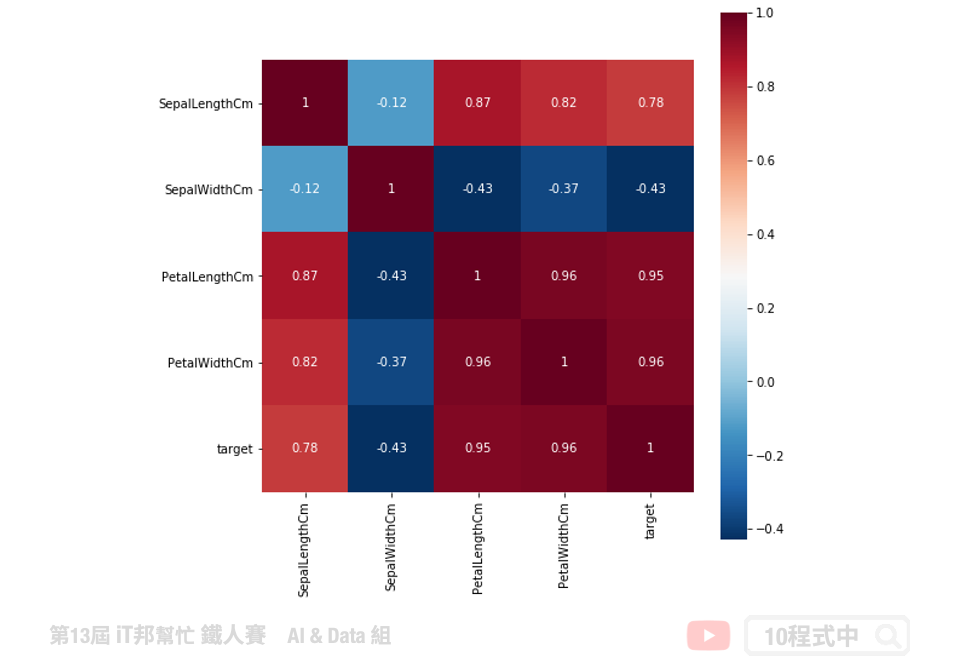
透過 pandas 的 corr() 函式可以快速的計算每個特徵間的彼此關聯程度。其區間值為-1~1之間,數字越大代表關聯程度正相關越高。相反的當負的程度很高我們可以解釋這兩個特徵之間是有很高的負
關聯性。
# correlation 計算
corr = df_data[['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']].corr()
plt.figure(figsize=(8,8))
sns.heatmap(corr, square=True, annot=True, cmap="RdBu_r")
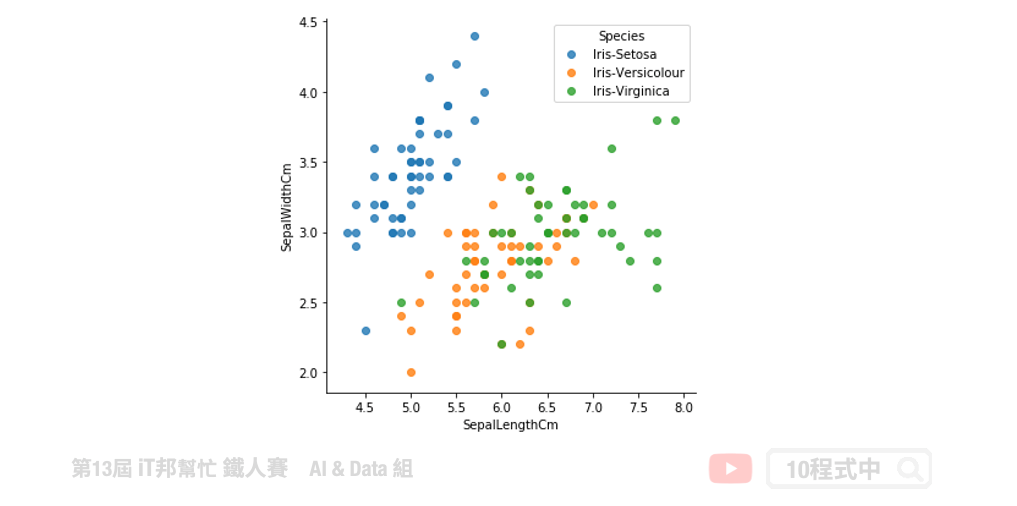
透過散佈圖我們可以從二維的平面上觀察兩兩特徵間彼此的分佈狀況。如果該特徵重要程度越高,群聚的效果會更加顯著。
sns.lmplot("SepalLengthCm", "SepalWidthCm", hue='Species', data=df_data, fit_reg=False, legend=False)
plt.legend(title='Species', loc='upper right', labels=['Iris-Setosa', 'Iris-Versicolour', 'Iris-Virginica'])
透過箱形圖可以分析每個特徵的分布狀況以及是否有離群值。我們利用箱形圖來表示四分位數來觀察數據分散情況。箱形的兩端為第一個四分位數涵蓋25%之資料(Q1)與第三個四分位數涵蓋75%之資料(Q3),而箱形圖的中間線為中位數顯示涵蓋前50%資料之位置。箱形上虛線的端點為極大值,箱型下虛線的點為極小值。
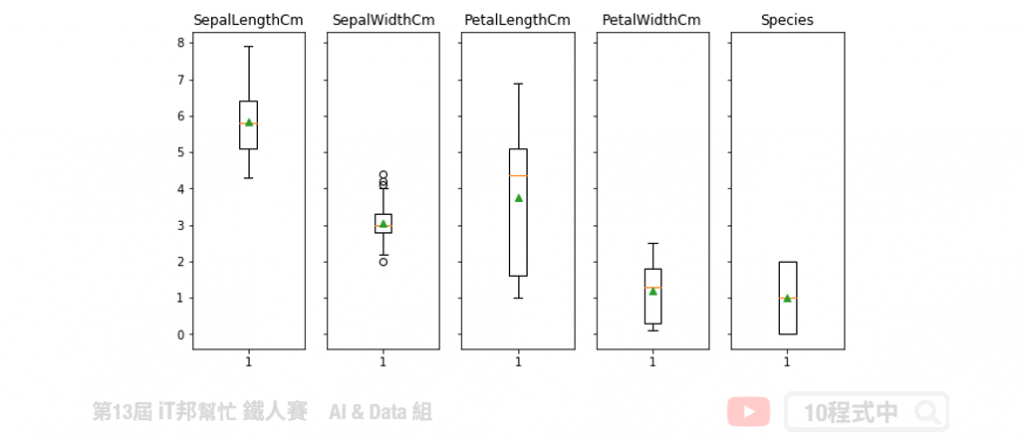
今天所介紹的資料視覺化都是很基礎的資料探索方式。只要簡單的幾個步驟就能幫助你了解收集的資料,並利於後面資料處理及建模。未來我再帶給各位一些不錯的資料視覺套件,幫助你對資料逕行更多的視覺分析。
文章同時發表於: https://andy6804tw.github.io/crazyai-ml/3.你真了解資料嗎試試看視覺化分析吧
如果你對機器學習和人工智慧(AI)技術感興趣,歡迎參考我的線上免費電子書《經典機器學習》。這本書涵蓋了許多實用的機器學習方法和技術,適合任何對這個領域有興趣的讀者。點擊下方連結即可獲取最新內容,讓我們一起深入了解AI的世界!
👉 全民瘋AI系列 [經典機器學習] 線上免費電子書
👉 其它全民瘋AI系列 這是一個入口,匯集了許多不同主題的AI免費電子書

